
Devenez Big data engineer Data scientist
37 jours
100% finançable
Formation RNCP
Jours de formation
Solutions de financement
Une formation pour qui ?
La formation Big data enginnering et data scientist s’adresse aux :
- Directeurs/Chefs de projet ou Responsable métier
- Responsable système d’informations
- Développeurs informatiques
- Consultants en business intelligence
- Ingénieurs d’étude, de recherche et développement, Architecte système et logiciel
- Consultants techniques, Consultants business
- Statisticiens et Mathématiciens
La formation Big data enginnering et data scientist se distingue par la maîtrise de multi-compétences en Gestion de donnés massives.
Cette formation va vous permettre d’acquérir les compétences pour devenir Full Stack Big Data, à savoir : l’architecture et l’engineering Big Data, le stockage NoSQL, l’analyse et la science de données, la visualisation de données, le déploiement en Cloud d’une solution Big Data et l’administration d’une plateforme Big Data.
Maîtriser le concept Big Data pour la recherche, l’analyse, le partage et le stockage de données massives.
Explorer le potentiel BIG DATA au service de tous les métiers (Marketing, Contrôle de Gestion, Ressources humaines, Renseignement, Santé, Banque, Assurance…)
Pré-requis
- Avoir suivi la formation Développeur Java J2EE ou Microsoft.NET serait un plus
- Avoir une expérience des bases de données relationnelles
- Posséder des connaissances approfondies en statistique est un plus
- Etre capable de travailler en équipe avec un sens d’écoute et d’analyse
- Avoir des connaissances en Python
A l’issue de la formation Big Data enginnering et Data scientist, le certifié sera en mesure de :
- Identifier les besoins et la problématique des directions métiers
- Maîtriser les technologies spécifiques au Big Data comme Hadoop, Pig, Hive, Spark, Yarn, Kafka, ELK, ou Cloudera
- Mettre en place un Data Lake
- Maîtriser les bases de données NoSQL : MongoDB, Cassandra, Neo4j, hBase, Redis…
- Maîtriser les technologies spécifiques à la science, à l’analyse ainsi qu’à la visualisation de données : Statistiques, Machine Learning, Deep Learning, langage R, Python, Tableau, PowerBI, R Shiny…
- Maîtriser le déploiement des solutions Big Data sur le Cloud : AWS, GCP, Microsoft Azure…
- Maîtriser la science de données et l’IA « Intelligence Artificielle » : Sprak Mlib, Scala, PySpark, RPA « Robotic Process Automation »
- Construire des modèles prédictifs pour répondre à la problématique
- Construire des algorithmes pour améliorer les résultats de recherche et de ciblage
- Trouver et rassembler l’ensemble des sources de données structurées ou non structurées nécessaires à l’analyse pertinente
- Identifier les opportunités à travers l’open data et les cas d’usage métiers
- Concevoir un projet Big Data (acquisition et stockage des données, traitement distribué, analyse de données à large échelle)
- Maîtriser les technologies par des études de cas concrètes
- Maîtriser les enjeux juridiques et liés à la protection des données
Programme détaillé
01- Big Data: Enjeux et perspectives
Voir le programme
Big Data : Introduction
- Introduction
- Types du big data
- Du SQL au NoSQL
- Caractéristiques techniques des 5V
- Technologies Big Data
- Languages Big Data
- Acteurs principaux du Big Data
- Différents métiers du Big Data
- Collecte et traitement des données structurées, semi-structurées et non-structurées
- Stockage des données
- Diffusion des données
- Traitements en temps réel ou différé: Kafka
- Architectures réparties : Hadoop
- Architecture Cloud / Scalabilité
- Impact de l’usage du Big Data
- Création de la valeur à partir des données
- Exemple d’architecture Big Data
Enjeux du Big Data
- Enjeux du big data en france
- ROI et Big Data
Marché Du Big Data
- Marché de la data au niveau mondial
- Évolutions et les acteurs de la chaine de l’offre Big Data
- Enjeux stratégiques (création de la valeur)
- Opportunités pour les entreprises de services informatiques
Impacts du Big Data sur l’entreprise
- Transformation de la relation client
- Transformation de l’organisation de l’entreprise
- Transformation du produit final
- Chaîne des valeurs, développement des nouvelles activités
- Productivité et optimisation des dépenses
- Apparition des nouveaux rôles/métiers (data scientists et CDO)
- Compétences nouvelles à acquérir
Solutions technologiques du Big Data
- L’écosystème de la plateforme Hadoop : Pig, Flume, Zookeeper, HBase, Oozie, YARN,
MapReduce… - Les modes de stockage (NoSQL, HDFS) / principes de fonctionnement de MapReduce
Méthodologie de gestion d’un projet Big Data
- Mise en place d’un projet Big Data
- Méthodologies recommandées pour lancer un projet Big Data
- Calcul du retour sur investissement d’un projet Big Data
Atelier pratique
02- Introduction à l’Architecture Big Data
Voir le programme
Introduction à l’architecture Big Data
- Définition du Big Data
- Comprendre le volume
- Besoin Big Data
- Introduction à l’architecture Big Data
- Distribution des données
- Rôles d’un projet Big Data
- Atelier pratique
Ecosystème Hadoop
- Technologies et Outils Big Data
- Découvrir l’écosystème Hadoop
- Les distributions Hadoop
- Atelier pratique
Mode de stockage HDFS et Base NoSql
- Comprendre HDFS
- HadoopFS
- Caractéristiques de HDFS
- Les modes de stockage HDFS
- Services HDFS
- Opération HDFS
- Administration d’un cluster HDFS
- Comprendre NoSQL
- Les modes de stockage NoSQL
- Choix du type de la Base de donnée NoSQL
- Atelier pratique
Principes du Traitement MapReduce
- Principes de fonctionnement de MapReduce
- Fonction map()
- Fonction reduce()
- Conception d’un MapReduce
- Atelier pratique
Architecture applicative
- Introduction
- Différentes étapes de gestion des données (Cycle de vie des données dans le Big Data)
- Définition du processus d’ingestion des données
- Outil disponibles sur le marché
- Modèle d’architecture applicative d’une solution Big Data
- Atelier pratique
Architecture technique
- Introduction à l’architecture technique
- Traitement de données
- Qualité des données (Data Quality)
- Architectures réparties (Clustering Hadoop)
- Atelier pratique
Modèles d’Architectures Big Data
- Introduction
- Architecture Datalake
- Architecture Lambda
- Architecture Kappa
- Architecture pour l’internet des objets (IoT)
- Atelier pratique
Critères de choix d’une architecture Big Data
- Introduction
- Critères de choix
- Le type de traitement
- L’utilisateur final des données
- La source des données (où les données sont générées)
- Format du contenu
- Types des données à traiter
- Fréquence et taille des données
- Méthodologie de traitement des données
- Le choix du matériel
- Récapitulatif des critères du choix d’une architecture big data
- Atelier pratique
03- NoSQL
Voir le programme
Introduction aux Bases de données NoSQL
- Histoire de NoSQL
- Comprendre le modèle NoSQL
- NoSQL Vs BDR
- Propriétés ACID
- Propriétés BASE
- Théorème de Brewer ou de CAP
- Caractéristiques NoSQL
Atelier pratique
Principaux modèles de BD NoSQL
- Familles des Bases de Données NoSQL
- Modèle NoSQL « Clé-Valeur »
- Modèle NoSQL orienté Colonne
- Modèle NoSQL orienté Document
- Modèle NoSQL orienté Graphe
- Bases de données NoSQL
- Comparatif des bases de données NoSQL
- Récapitulatif des types de schéma de données NoSQL
- HBase
- MongoDB
- Cassandra
- Redis
- Couchbase
- Elasticsearch
- Riak
Atelier pratique
Choix d’une Base de données NoSql
- Choisir une base de données NoSQL
- Classification des bases de données les plus utilisées
Atelier pratique
04- Hbase / Mongo DB / H Base / Cassandra / Redis
Voir le programme
Introduction à Hbase
- Définition de Hbase
- Hadoop vs Hbase
- Caractéristiques de Hbase
- Quand utiliser HBase
- Importance des bases de données NoSQL dans Hadoop
- Autres type de stockage NoSQL
- Comment HBase diffère des autres modèles NoSQL
- Quelle base de données NoSQL choisir?
- HBase Vs Hive
- HBase VS RDBMS
Atelier pratique
Architecture de Hbase
- Mécanisme de stockage dans HBase
- Stockage orienté colonne vs orienté ligne
- Modèle de données HBase
- Avantages de l’architecture Apache HBase
- Architecture HBase et ses composants importants
- Comment les composants Hbase fonctionnent ensemble
- Lecture et écriture dans HBase
- Récapitulatif des étapes d’écriture Hbase
- HBASE vs HDFS
- Cas d’utilisation de HBase
Atelier pratique
Installation de Hbase
- Modes d’installation d’Apache HBase
- Configuration de pré-installation
- Création d’un utilisateur Hadoop
- Configuration SSH et génération de clés
- Mise en place de Java
- Mise en place de Hadoop
- Installation de Hbase
- Comment télécharger la version stable du fichier tar Hbase
- Installation de HBase en mode autonome (Standalone)
- Installation de HBase en mode Pseudo distribué
- Installation de HBase en mode entierement distribué
- Dépannage de l’installation de HBase
Atelier pratique
Commandes générales Hbase SHELL
- La commande status
- La commande version
- La commande table_help
- La commande whoami
Atelier pratique
Manipulation des tables avec HBASE
- Commandes de gestion des tables
- Créer une table à l’aide de HBase Shell
- Créer une table à l’aide de l’API java
- Désactiver une table à l’aide de HBase Shell
- Désactiver une table à l’aide de l’API java
- Activation d’une table à l’aide de HBase Shell
- Activation d’une table à l’aide de l’API java
- Décrire et modifier une table à l’aide de Hbase Shell
- Décrire et modifier une table à l’aide de l’API java
- Existence d’une table à l’aide de HBase Shell
- Existence d’une table à l’aide de l’API java
- Suppression d’une table à l’aide de HBase Shell
- Suppression d’une table à l’aide de l’API java
- Fermer une table à l’aide de HBase Shell
- Fermer une table à l’aide de l’API java
Atelier pratique
Insérer et récupérer des données dans HBase: exemples get (), put (), scan ()
- Insertion ou écriture de données dans la table HBase: Shell
- Insertion de données à l’aide de l’API Java
- Mise à jour des données à l’aide de HBase Shell
- Mise à jour des données à l’aide de l’API Java
- Lecture de données à l’aide de HBase Shell
- Lecture de données à l’aide de l’API Java
- Suppression d’une cellule spécifique dans un tableau à l’aide de HBase Shell
- Suppression d’une cellule spécifique dans un tableau à l’aide de l’API Java
- Scanner à l’aide de HBase Shell
- compter et tronquer
- Sécurité
Atelier pratique
Avantages et limitations de Hbase
- Goulot d’étranglement des performances
- Avantages de HBase
- Limitations avec HBase
Introduction
- Stockage NoSQL
- Caractéristiques des bases NoSQL : CAP
- Choix d’une base de données NoSQL
- Bases de données orientées documents
- Historique et Présentation de MongoDB
- Cas d’utilisation de MongoDB
- Structure des données : notions de documents, de collections de valeurs
- Le format JSON
- Stockage de JSON
- JavaScript pour manipuler du JSON
Atelier pratique
Installation et configuration de MongoDB
- Plateformes supportées
- Installation de MongoDB sur Windows
- Choix de la version
- Téléchargement de MongoDB pour Windows
- Exécution
- Configuration
- Lancement de Mongo DB
- Connection à MongoDB
- Installation de MongoDB sur Linux
- Choix de la version
- Téléchargement de MongoDB pour Windows
- Exécution
- Configuration
- Lancement de Mongo DB
- Connection à MongoDB
Atelier pratique
Prise en main de MongoDb
- Utilisation de l’invite interactive
- Commandes de manipulation de base de données
- Utilisation d’un client graphique
- Importation d’une collection
- Manipulation du format BSON
- Comprendre le type ObjectId
Atelier pratique
Administration de MongoDB
- Sauvegarde des données
- Configuration de la journalisation
- Mise en place d’une réplication
- Configuration de la réplication
- Teste de la réplication
- Mise en place du sharding
- Configuration d’une collection pour le sharding
Atelier pratique
Manipulation des documents dans MongoDB
- Insérer un document
- Modifier et supprimer un document
- Utiliser une transaction
- Chercher des documents avec FIND()
- Comparer FIND() et SELECT en SQL
- Utiliser les opérateurs du FIND()
- Indexer pour améliorer les performances
Atelier pratique
MongoDB avancé
- Comprendre le framework d’agrégation
- Découvrir les étapes de l’agrégation
- Découvrir les opérateurs des Pipeline d’agrégation
Atelier pratique
Introduction à Cassandra
- Base de données NoSQL
- Définition de Cassandra
- Caractéristiques de Cassandra
- Modèle de données Cassandra
- Cassandra vs RDBMS
- Cassandra vs Hadoop
- Cassandra vs HBase
- Cassandra vs MongoDB
- Cassandra Cqlsh
- Commandes Shell
- Atelier pratique
Architecture de Cassandra
- Composants de l’architecture de Cassandra
- Composants de l’architecture de Cassandra
- Cassandra Keyspace (Création, modification et suppression d’un Keyspace)
- Réplication de données dans Cassandra
- Atelier pratique
Installation et configuration de Cassandra
- Installation et configuration de Cassandra sur Windows
- Installation et configuration de cassandra sur Linux
- Installation et configuration de cassandra avec Docker
- Atelier pratique
Le langage CQL (Cassandra Query Language)
- Modèle de données de Cassandra
- API de Cassandra
- Types de données CQL
- Atelier pratique
Manipulation de tables avec Cassandra
- Création de tables
- Modification de tables
- Suppression ds tables
- Tronquer une table
- Création d’un index
- Suppression de l’Index
- Lot (Batch)
- Atelier pratique
Manipulation des données avec CQL
- Création de données
- Mise à jour des données
- Lecture des données
- Suppression de données
- Définition des types de données complexes
- Insertion des données dans des types complexes
- Modification les types de données complexes
- Atelier pratique
Les Clusters avec Cassandra
- Les clusters
- Démarrage d’un cluster avec Docker Compose
- Surveillance de l’ajout des nœuds
- Obtention d’informations avec nodetool
- Maîtrise de la syntaxe de création de table
- Définition d’une clé de partition et de clustering
- Modélisation des données
- Atelier pratique
05- Apache Hadoop
Voir le programme
Section 1: Introduction à l’écosystème Hadoop
- Aborder cette formation
- Découvrir NoSQL
- Définir le Big Data
- Comprendre l’histoire d’Hadoop
- Parcourir l’écosystème Hadoop
- Différencier les distributions Hadoop
- Comprendre le NoSQL
- Définition du Big Data
- Architecture de Hadoop
- L’Écosystème de Hadoop
- Rôle des différents composants de l’écosystème Hadoop
- Rôle des collecteurs de données
- Distributions d’Hadoop
Section 2: Installation de l’environnement Hadoop
- Installation de l’environnement Hadoop VM Ubuntu
- Installation de l’environnement Hadoop sur Windows
- Différencier les distributions Hadoop
- Découvrir Cloudera Hadoop
- Démarrer une QuickStart VM
- Travaux pratique: Installation Hadoop
Section 3: HDFS – La couche de stockage
- Comprendre le HDFS
- Découvrir HadoopFS
- Assimiler les principes du HDFS
- Appréhender les services HDFS
- Comprendre les opérations HDFS
- Configuration de HDFS
- Demarrage de HDFS
- Administrer le cluster HDFS
- Découvrir la gestion des services HDFS
- 0Manipuler les fichiers en ligne de commande
- Exécuter des opérations en Java
- Utiliser les InputStream Java
- Accéder à HDFS avec WebHDFS
- Caractéristiques de HDFS
- Architecture de HDFS
- Rôle de HDFS
- Opérations HDFS
- Listing des fichiers dans HDFS
- Insertion des données dans HDFS
- Extraction des données du HDFS
- Arrêt du HDFS
Section 4: Fonctionnement de MapReduce
- Appréhender les principes de base
- Découvrir la fonction map()
- Utiliser la fonction reduce()
- Concevoir un MapReduce
- Développer le mapper
- Développer le reducer
- Créer un jeu de données
- Créer le driver
- Lancer un MapReduce en Java
- Suivre l’évolution du MapReduce
- Développer un MapReduce en PHP
- Lancer des MapReduce avec Hadoop Streaming
- Principes de base de MapReduce
- Architecture MapReduce
- Fonction map()
- Fonction reduce()
- Conception d’un MapReduce
- Développer le mapper
- Développer le reducer
- Création d’un jeu de données
- Création d’un driver
- Lancer un MapReduce en Java
- Suivi de l’évolution du MapReduce
- Développement d’un MapReduce en PHP
- Lancement des MapReduce avec Hadoop Streaming
- TP : Fonctionnement de MapReduce
Section 5: Base de données NoSQL HBase
- Identifier les cas d’utilisation de HBase
- Comprendre le modèle Hbase
- Administrer HBase
- Appréhender les opérations HBase
- Gérer les services avec des interfaces web
- Lancer des commandes HBase dans le terminal
- Filtrer les résultats d’un scan
- Utiliser HBase en Java
- Utiliser HBase dans les MapReduce
- Définition de Hbase
- Hbase avec Hadoop
- Cas d’utilisation de HBase
- Comprendre le modèle Hbase
- Installation de Hbase
- Architecture
- Composants Hbase (Region, Region Server, Region Split)
- Lecture et écriture dans Hbase
- API Shell
- API Java
- TP : Base de données NoSQL HBase
Section 6: Apache Oozie -Ordonnanceur de WorkFlow
- Définition de Oozie
- Caractéristiques Oozie
- Fonctionnement de Oozie
- Actions Oozie
- Oozie Job
- Oozie workflow
- Coordinateur Oozie
- Paramètre Oozie
- Monitoring Oozie
- Packaging et déploiement d’une application de workflow Oozie
Section 7: Collecte de données avec Apache Sqoop
- Introduire scoop anglais
- Importer les données avec scoop
- Définition de Sqoop
- Cible des imports dans le cluster
- Architecture de Sqoop
- Fonctionnement de Sqoop
- Exemple d’import vers HDFS
- Exemples d’import vers Hive
- Exemple d‘exports
Section 8 : travaux pratiques: Développement d’une application Big Data avec Hadoop
- Mission 1: Conception de l’application
- Découper l’application
- Exploiter les données
- Concevoir la base de données HBase
- Parser le fichier d’entrée dans un mapper
- Écrire dans HBase avec un reducer
- Mettre en place des clés composites
- Utiliser les clés composites
- Lancer un modèle MapReduce d’import
Mission 2: Développement des modèles MapReduce
- Lire les données de HBase dans un mapper
- Agréger les données dans un reducer
- Suivre les modèles MapReduce
- Déboguer les modèles MapReduce
- Explorer les sources d’Hadoop
- Réaliser des jointures de données
- Résoudre le problème du secondary sort
- Optimiser ses modèles MapReduce
Mission 3: Développement des modèles MapReduce
- Mettre en place un workflow Oozie
- Lancer un workflow Oozie
- Filtrer les données de HBase
- Exporter dans MySQL grâce à Sqoop
- Lancer son workflow avec l’API HTTP REST
- Coupler l’application avec une interface web
06- Apache Spark
Voir le programme
Introduction à Apache Spark
- Apache Spark
- MapReduce VS Spark
- Caractéristiques d’Apache Spark
- Architecture d’Apache Spark
- Anatomie d’une application Spark
- Interaction avec Spark
- Spark sur Hadoop
- Composants de Spark
Atelier pratique
Installation de Spark
- Préparation d’une VM Linux
- Télécharger Apache Spark
- Installation d’Apache Spark : redhat /CentOS
- Installation d’Apache Spark : Windows
- Installation d’Apache Spark : Mac OS
- Installation d’Apache Spark : Ubuntu /Debian
Atelier pratique : Installation Spark
Resilient Distributed Datasets ( RDDs )
- Introduction aux RDDs (Resilient Distributed Datasets)
- Exemple d’un RDD
- Caractéristiques des RDDs
- Liaison avec Spark (Scala/Java/Python)
- Création d’un RDD
- Opérations RDD
- Actions RDD
- Transformation RDD
Atelier pratique
Spark streaming
- Définition
- Exemple Scala, Java et Python
- Concepts de base
- Initialisation de StreamingContext
- Flux discrétisés (DStreams)
Atelier pratique
Spark SQL
- Caractéristiques de Spark SQL
- Architecture Spark SQL
- Appréhender les abstractions de données de Spark
- Exploiter la Spark Session
- Créer un Data Frame
- Manipuler le DataFrame
- Comprendre les formats de stockage
- Construire un jeu de données
- Importer un fichier Avro
- Joindre des DataFrames
- Sauvegarder au format Parquet
- Employer la syntaxe select
- Utiliser un Dataset
- Exécuter un programme avec spark-submit
- Choisir une distribution Spark
- Conclure sur Apache Spark
Atelier pratique
07- Apache Kafka
Voir le programme
Introduction à Apache kafka
- Présentation de Kafka
- Intérêt d’Apache Kafka
- Les API de Kafka
- Terminologies de Kafka
- Atelier pratique
Architecture d’Apache kafka
- Architecture du cluster Kafka
- Topic
- Broker
- Zookeeper
- Producers
- Consumers
- Kafka WORKFLOW
Installation et configuration de Apache Kafka
- Installation et configuration d’Apache Kafka
- Installation de Java
- Installation de Zookeeper
- Installation de Kafka
- Atelier pratique: Installation
Commande Line Interface (CLI)
- Démarrez le serveur Kafka
- Lister tous les sujets
- Créer un topic
- Décrire un topic
- Publier des messages sur un topic
- Consommer des messages
- Modifier les sujets d’Apache Kafka
- Atelier pratique: CLI
Développement Kafka avec Java
- Introduction à la programmation Kafka
- Kafka APIs
- Création d’un projet Kafka
- Java producer
- Rappels des producers Java
- Producer Java avec clés
- Java consumer
- Consumer Java au sein d’un groupe de consumers
- Consumer Java avec threads
- Le consumer Java recherche et attribue
- Compatibilité de client bidirectionnelle
- Atelier pratique: Développement Kafka
Kafka Stream
- Introduction à Kafka Stream
- Concepts de Kafka Stream
- Architecture de Kafka Stream
- Démo: Application wordcount avec kafka stream
- Atelier pratique: KStream
08- Elastic Stack ELK
Voir le programme
Introduction à la suite ELK (ELK Stack)
- Aperçu sur la suite ELK
- Autres outils en relation avec ELK
- Rôle de Elastic Stack
- Installation de la suite ELK
- Installation de la suite ELK sur Windows
- Installation de la suite ELK sur Docker
Eléments du Stack ELK
- Elasticsearch: Le noyau
- Kibana: L’outil utilisateur
- Logstash: L’outil d’ingestion
- Beats: Transfert de données
- X-Pack: Le pack de fonctionnalités
Cas d’utilisation la suite ELK
- Gestion des logs
- Aperçu sur la gestion des logs
- Analyse des métriques
- Aperçu sur l’analyse des métriques
- Recherche de Sites et d’applications
- Analyse de sécurité
- Aperçu sur l’analyse de sécurité
- Monitoring des performances des applications
Chargement des données
- Données de chargement en masse
- Chargement d’échantillons de données
- Définition des types de données
Interrogation des données
- Requêtes simples
- Requêtes au niveau du terme
- Analyse et tokenisation
Analyse des données
- Agrégations de base
- Filtrer les agrégations
- Percentiles et histogrammes
Présentation de vos Insights
- Présentation et configuration de Kibana
- Création de visualisations dans Kibana
- Création de tableaux de bord dans Kibana
Dépannage du Stack
- Quand les choses vont mal
- Dépannage des ressources
Atelier cas pratique
- Installation et configuration (Serveur ElasticSearch, Mettre en place un cluster , Les rôles des
noeuds)
09- Gouvernance et Sécurité
Voir le programme
Introduction à la Gouvernance des données
- Rôle des données au 21e siècle
- Définition et principes de base de la gouvernance des données
- Gouvernance des données Vs Gestion des données
- Avantages de la gouvernance des données
- Gouvernance des données dans le cloud
- Outils de gouvernance des données
- Les étapes de la gouvernance des données
Atelier pratique
Déploiement de la gouvernance des données
- À qui appartiennent les données et pourquoi est-ce important?
- Rôles dans le domaine de la gouvernance des données
- Conception du processus de gouvernance des données
Atelier pratique
Gestion d’un programme de gouvernance des données
- Gestion et maintien de la gouvernance des données
- Suivi et mesure de votre programme
Atelier pratique
10- Introduction à la data science
Voir le programme
Introduction à la Data Science
Big data
Deep learning
- Perceptron
- Réseaux neuronaux multicouches (MLP)
- Réseaux neuronaux convolutifs (CNN)
- Réseaux neuronaux récursifs (RNN)
Machine Learning
- Apprentissage automatique supervisé/ non supervisé
- Algorithmes du Machine Learning
Principes de la data science
- Approche fonctionnelle de base
- Variables prédictives
- Variables à prédire
- Fonctions hypothèses
- Estimateurs (biais et variances)
- Compromis biais – variance
- Fonctions de perte
- Régularisation des paramètres
- Optimisation des paramètres
Clustering
- k-moyens (kMeans)
- Clustering hiérarchique
- Approche DBSCAN
Classification
- Régression logistique
- Machines à vecteurs de support (SVM)
- Arbres de décisions
- K plus proches voisins (kNN)
Traitements en Data Science
- Compressions des données
- Réglages des modèles
Principes de l’apprentissage d’ensemble
- Forêts aléatoires
- gradient boosting
Principes de la régression
- Explorations des données régressives
- Performance des modèles de régression
Atelier Cas pratique
11- Python pour la data science
Voir le programme
Opérations basiques avec Python
- Python pour la data science
- Comprendre l’importance de la data science
- Expliquer le choix de Python
- Installation de Python
Opérations basiques avec Python
- Opérations basiques sur les listes
- Opérations avancées sur les listes
- Les dictionnaires
- Les compréhensions
Chargement et préparation des données
- Intérêt du prétraitement de données
- Chargement des fichiers Excel et CSV
- Chargement d’un fichier JSON
- Interrogation d’une base de données SQL Server
- Concaténation de différentes sources de données
- Fusion de différentes sources de données
- Manipulation des données manquantes
- Maîtrise des statistiques descriptives avec NumPy
- Maîtrise des statistiques descriptives avec Pandas
Manipulation des données
- Différents types de données
- Manipulation des données quantitatives avec NumPy
- Techniques d’encodage
- Manipulation des données textuelles avec Pandas
- Manipulation des données textuelles avec NLTK
- Utilisation des séries temporelles
- Manipulation des images
Atelier pratique Visualisation des donnée
Visualisation des données
- Découvrir les bases de la visualisation de données
- Matplotlib
- Seaborn
- Bokeh
- Aller plus loin avec Matplotlib
Initiation au Web scrapig
- Web scraping
- Exploration d’un document HTML avec Beautiful Soup
- Objets Tag et NavigableString
- Aller plus loin avec le web scraping
- Pratique du web scraping
Initiation aux algorithmes de machine learning
- Régression linéaire
- Mise en œuvre la régression linéaire
- Algorithme SVM
- Utilisation de l’algorithme SVM
- Classification naïve bayésienne
- Pratique de la classification naïve bayésienne
- Algorithme des k-moyennes
- Utilisation de l’algorithme des k-moyennes
- Analyse en composante principale PCA
Deep learning avec Keras et TensorFlow
- Définition du Deep learning
- Concepts du deep learning
- TensorFlow
- Keras
- Compréhension et préparation des données
- Déploiement du modèle
Atelier Pratique
12- Machine Learning
Voir le programme
Initiation au machine Learning
- Fondements du Machine Learning
- Introduction au Machine Learning
- Groupes de Machine Learning
- Besoins du Machine Learning
- Cycle de vie du Machine Learning
- Identification des biais cognitifs humains
Classification du machine Learning
- Théorie du Naïve Bayes
- Régression logistique binomiale
- Théorie k-NN
- Arbres de classification
- Forêts d’arbres de décision
- Support vector machine
Régression linéaire avec Python
- Définition de la régression
- Régression linéaire univariée
- Régression linéaire multivariée
- Régression linéaire polynomiale
- Régressions régularisées
- Programmer une régression linéaire en Python
- Utilisation des expressions lambda et des listes en intention
- Afficher la régression avec MathPlotLib
- L’erreur quadratique
- La variance
- Le risque
Initiation au clustering
- Définition du clustering
- Méthode k-means
- Clustering hiérarchique
Initiation aux Règles d’association
- Définition des règles d’association
- Initiation à la méthode A priori
- Évaluation des règles d’association candidates
Réduction dimensionnelle
- Définition de la réduction dimensionnelle
- Utilisation des méthodes de sélection de variables
- Méthode ACP
- Méthode ADL
Algorithmes Du Machine Learning
- Initiation à l’ensemble learning
- Apprentissage par renforcement
- Régression linéaire simple et multiple
- Régression polynomiale
- Séries temporelles
- Régression logistique et applications en scoring
- Classification hiérarchique et non hiérarchique (K-Means)
- Classification par arbres de décision ou approche Naïve Bayes
- Ramdom Forest (développement des arbres de décision)
- Gradiant Boosting
- Réseaux de neurones
- Machine à support de vecteurs
- Deep Learning : exemples et raisons du succès actuel
- Text Mining : analyse des corpus de données textuelles
Atelier cas pratique
Numpy Et Scipy
- Tableaux et matrices
- Algèbre linéaire avec Numpy
- Numpy et MathPlotLib
Scikit learn
- Machine Learning avec SKLearn
- Régression linéaire
- Création du modèle
- Echantillonnage
- Randomisation
- Apprentissage avec fit
- Prédiction du modèle
- Metrics
- Choix du modèle
- PreProcessing et Pipeline
- Régressions non polynomiales
Test et validation des algorithmes
- Validation des algorithmes
- Atelier cas pratique
- Techniques de ré-échantillonnage en jeu d’apprentissage, de validation et de test
- Mesures de performance des modèles prédictifs
- Matrice de confusion, de coût et la courbe ROC et AUC
Atelier cas pratique
13- Deep Learning avec Python – Keras ou Tensor Flow
Voir le programme
Introduction au Deep Learning
- IA et deep learning
- Architecture du deep learning
- Fonctionnement d’un modèle de deep learning
- Architecture d’un réseau de neurones
- Construction d’un réseau de neurones
- Apprentissage du réseau de neurones
- Concepts de Keras
- Deep learning avec Keras
Machine Learning et Deep Learning
- Apprentissage automatique
- Importation des données
- Préparation des données
- Stabilisation de l’apprentissage d’un modèle avec Keras
- Sauvegarde et réutilisation d’un réseau avec Keras
- Sauvegarde d’un réseau
Performance des algorithmes
- Paramètres de l’apprentissage
- Amélioration de l’apprentissage avec Keras
- Stratégie d’amélioration
- Accélération des calculs avec le cloud computing et le GPU
- Accélération des calculs avec le cloud computing et le TPU
Atelier cas pratique
Analyse de textes avec Keras
- Word embedding
- Application du deep learning sur les textes
- Préparation des documents avec Keras
- Écriture d’un modèle de word embedding avec Keras
- Classification des documents et interprétation des résultats
- Amélioration d’un modèle d’analyse de textes avec Keras
Reconnaissance des images avec Keras
- Définition de la convolution
- Application de la convolution sur des images
- Application du deep learning sur des images
- Fonctionnement du pooling
- Architecture d’un réseau à convolution
- Jeu de données d’images
- Préparation des images pour l’analyse
- Découverte de l’OCR
- Reconnaissance des images
- Augmentation des données
- Préparation des données pour réutiliser les meilleurs modèles de Keras
- Réutilisation des meilleurs modèles existants avec Kera
Atelier cas pratique
________
Initiation au deep learning
• Comprendre le succès du deep learning
• Appréhender le machine learning
• Suivre une expérience en data science
• Comprendre le perceptron
• Comprendre le réseau de neurones
• Concevoir un réseau de neurones
• Entraîner un réseau de neurones
• Suivre les itérations de l’algorithme de rétropropagation
• Découvrir le deep learning
• Aborder l’architecture des réseaux de neurones
• Installer Anaconda
• Installer TensorFlow 2
• Lien entre l’IA et le deep learning
• Initiation au deep learning
• Structure d’un modèle de deep learning
• Comprendre le fonctionnement d’un modèle de deep learning
• Deep learning avec python
Atelier cas pratique
Composants de base de TensorFlow
• Prendre en main TensorFlow et les structures de données
• Pourquoi Tensorflow 2.0 ?
• Installation of Tensorflow 2.0
• Utiliser Tensorflow 2.0 avec ANACONDA/Google Colab
• Tensorflow – les structures de données
• Calculs de base sur les tenseurs
• Indexage – Indexation
• Manipulation de formes
• Introduction aux variables
• Introduction aux fonctions
Atelier cas pratique
Mettre en œuvre Sequential API de TensorFlow.Keras
• Créer un réseau de neurones
• Créer un réseau de neurones de type MLP
• Accéder aux informations des couches d’un réseau de neurones
• Initialiser les poids et les biais d’un réseau de neurones
• Compiler et entraîner un réseau de neurones
• Comprendre les données de validation
• Traiter les données déséquilibrées
• Analyser les résultats
• Prédire avec un réseau de neurones multiclasse
• Charger les données pour une régression
• Réaliser un réseau de neurones pour une régression linéaire
• Découvrir le Deep learning avec tf.Keras
• Régression linéaire avec tf.keras
• Régression linéaire avec tf.keras
• Régression non linéaire avec tf.keras
• Un exercice simple de classification
• Reconnaissance de l’écriture manuscrite au moyen du MLP
• Reconnaissance de l’écriture manuscrite au moyen du MLP
• Stabiliser l’apprentissage d’un modèle avec tf.Keras
• Classification des images de vêtements
Atelier cas pratique
Utiliser Functional API et Subclassing API
• Développer un modèle Functional API
• Développer un modèle Functional API avec plusieurs couches d’entrée
• Effectuer l’apprentissage d’un modèle Functional API avec plusieurs couches d’entrée
• Développer un modèle Functional API avec plusieurs couches de sortie
• Utiliser Subclassing API
Contrôler et monitorer un réseau de neurones
• Enregistrer un modèle
• Charger un modèle à partir d’un fichier
• Utiliser les callbacks prédéfinis lors de l’entraînement d’un réseau de neurones
• Configurer le critère d’arrêt de l’entraînement d’un réseau de neurones
• Visualiser les résultats avec TensorBoard
• Lancer le serveur TensorBoard
• Aborder les hyperparamètres d’un réseau de neurones
• Développer un programme pour fixer les hyperparamètres
• Utiliser GridSearchCV pour tester plusieurs paramètres
• Entraîner plusieurs réseaux de neurones avec GridSearchCV
• Gérer les hyperparamètres des réseaux de neurones
• Éviter le Sur-apprentissage
• La méthode “Early Stopping”
• Early Stopping dans Keras
• Stabiliser l’apprentissage d’un modèle
• Sauvegarder et réutiliser le modèle entraîné
Atelier cas pratique
Aborder CNN et le transfer learning
• Comprendre les CNN
• Éviter le surapprentissage avec le dropout
• Entraîner avec un CNN
• Réutiliser un réseau de neurones
• Implémenter le transfer learning
• Prédire avec le transfer learning
• Conclure sur TensorFlow
• Réseau à convolution CNN
• Comprendre l’architecture d’un réseau à convolution
• A quoi sert la convolution ?
• Méthode de sous échantillonnage : le Max-Pooling
• Les étapes de base pour créer le modèle CNN
• Application de CNN sur le jeu de données MNIST
• Comprendre l’apprentissage d’un réseau de convolutio
Atelier cas pratique
14- Mise en place d’un Data Lake
Voir le programme
Introduction aux données d’entreprise
- Données d’entreprise
- Importance de la qualité de la donnée
- Données du Big data
- Architectures Big Data
Atelier pratique
Introduction aux Data lake
- Présentation du Data lake
- Pertinence du Data lake dans une entreprise
- Avantage du Data lake
- Fonctionnement d’un Data Lake
- Différence entre le Data Lake et de Data Warehouse
- Défis du du Data lake
- Approches pour créer un Data Lake
- Conclusion
Atelier pratique
Architecture du Data Lake
- Architecture du Data lake
- Concepts clés du Data Lake
- Étapes de maturité du Data Lake
- Meilleures pratiques de l’architecture Data Lake
Atelier pratique
L’architecture Lambda basée sur Data Lake
- Introduction
- Couche d’ingestion de données
- Speed layer – traitement des données en temps quasi réel
- Couche de stockage de données – stocker toutes les données
- Serving layer – livraison et exportation de données
- Acquisition layer – Couche d’acquisition de données
- Messaging Layer – Couche de livraison de données
- Ingestion layer – Couche d’ingestion de données
- Exploration de la couche Lambda
- Magasins de données relationnelles
Atelier pratique
Écosystème Hadoop pour la mise en œuvre d’un Data lake
- Introduction
- Distributions Hadoop
- Facteurs de sélection d’un stack Big Data pour les entreprises
- Écosystème Hadoop pour un Data lake
Acquisition de données de données par lots avec Apache Sqoop
- Introduction
- Contexte dans Data Lake – Acquisition de données
- Fonctionnement de Sqoop
- Importation de données à l’aide de Sqoop
- Exportation de données à l’aide de Sqoop
- Connecteurs Sqoop
Atelier pratique
Acquisition de données de flux de données à l’aide d’Apache Flume
- Introduction
- Contexte dans Data Lake: acquisition de données
- Initiation à la Stream Data (Flux de données)
- Données Batch Vs données stream
- Acquisition de données de flux – cartographie technologique
- Fonctionnement de Flume
- Sqoop Vs Flume
Atelier pratique
Couche de messagerie utilisant Apache Kafka
- Introduction
- Contexte dans Data Lake – couche de messagerie
- Couche de messagerie
- Couche de messagerie – cartographie technologique
- Cycle de vie du flux de données
Atelier pratique
Traitement des données à l’aide d’Apache Flink
- Introduction
- Contexte dans un lac de données – couche d’ingestion de données
- Couche d’ingestion de données
- Data Ingestion Layer – cartographie technologique
- Fonctionnement de Flink
- Architecture Flink
Atelier pratique
Magasin de données à l’aide d’Apache Hadoop
- Introduction
- Contexte pour Data Lake – Stockage de données et lambda Batch Layer
- Stockage de données et Lambda Batch Layer
- Stockage de données et couche Lambda Batch – cartographie technologique
- Fonctionnement de Hadoop
- Architecture Hadoop
Atelier pratique
Magasin de données indexé à l’aide d’Elasticsearch
- Introduction
- Contexte dans Data Lake: stockage de données et lambda Speed layer
- Data Storage et Lambda Speed Layer
- Data Storage et Lambda Speed Layer: cartographie technologique
- Définition d’Elasticsearch
- Fonctionnement d’Elasticsearch
- Principes de l’architecture de base d’Elasticsearch
Atelier pratique
15- ElasticSearch
Voir le programme
Généralités sur les moteur de recherches
Présentation d’ElasticSearch
Installation et configuration
- Installation
- Configuration
- Vue générale de l’API REST
- Première indexation
- Première recherche
- Installation depuis les RPM
- Utilisation de l’interface X-Pack monitoring
- Premiers pas dans la console Sense
- Etude du fichier : elasticsearch.yml.
Indexation de documents
- Conception de l’index et de ses documents
- Indexer ou supprimer des documents avec l’API Rest
- Indexation en masse
- Version et gestion optimiste de la concurrence
- Présentation du stockage Lucene et refresh
- Autres fonctionnalités (routing, consistency, document enfant, …)
Mapping
- Définition et rôle du mapping
- Types de champs
- Champs prédéfinis
- Méta données d’un Index
Format des données
- Json
- Notions de types et de mapping
- Mise à jour des types ou re-indexation
Analyse et extraction de texte
- La base de l’extraction et analyse de texte
- Configuration et utilisation des Analyzers prédéfinis ou customisés
- API de vérification de l’analyse de texte
Recherche de documents
- Rechercher des documents avec l’API Rest
- Gestion des résultats
- Les requêtes de recherche
- Requêtes vs filtres
- Avantages des filtres
Kibana
- Présentation par les API d’administration et de supervision
- Objectifs
- Collecte de données
- Logs…
- Stockage dans ElasticSearch et mise à disposition dans une interface
Web de graphiques
- Démonstrations
Atelier cas pratique
Clustering
- Définitions
- Cluster
- Noeud
- Sharding
- Nature distribuée d’ElasticSearch
- Présentation des fonctionnalités
- Stockage distribué
- Calculs distribués avec ElasticSearch
- Tolérance aux pannes
Fonctionnement
- Notion de noeud maître
- Stockage des documents
- Shard primaire et réplicat
- Routage interne des requêtes
Gestion du cluster
- Outils d’interrogation
- /_cluster/health
- Création d’un index
- Définition des espaces de stockage (shard)
- Allocation à un noeud
- Configuration de nouveaux noeuds
- Tolérance aux pannes matérielles et répartition du stockage
- Gestion des pannes
- Fonctionnement en cas de perte d’un noeud
- Election d’un nouveau noeud maître si nécessaire
- Déclaration de nouveaux shards primaires
Mise en oeuvre X-Pack Security
- Présentation des apports de X-Pack Security
- Authentification
- Gestion des accès aux données (rôles)
- Filtrage par adresse IP
- Cryptage des données
- Contrôle des données
- Audit d’activité
Exploitation
- Gestion des logs
- ES_HOME/logs
- Paramétrage de différents niveaux de logs
- INFO
- DEBUG
- TRACE
- Suivi des performances
- Sauvegardes avec l’API Snapshot
Atelier cas pratique
16- RPA (Robotic Process Automation) avec Python
Voir le programme
Section 1. Tout automatiser avec Python
- Automatiser tout avec Python
- Course prerequisites
- Découvrir le RPA.
- Les opportunités pour l’entreprise.
- Les bénéfices de la RPA
- Quel outil faut-il utiliser ?
- Automatisation avec Python
- Préparation de l’environnement de travail
- TP
- Quiz
Section 2. Automatiser les interactions avec les fichiers, les dossiers et les terminaux
- Comment lire les fichiers
- Comment écrire des fichiers
- Exécuter les commandes du terminal
- Organiser les répertoires
- Le répertoire de travail actuel
- Chemins absolus et chemins relatifs
- Créer de nouveaux dossiers
- Le processus de lecture/écriture de fichiers
- Copier, déplacer, renommer et supprimer des fichiers et des dossiers
- Organiser les Dossiers
- Quiz
Section 3 : Automatiser l’accès aux données web – niveau de base
- La valeur du web scrapping
- Création et analyse d’une requête
- Explorer la structure HTML
- Comment isoler les données
- Préparation au grattage paginé
- Gratter le contenu paginé
- Web scraping
- Exploration d’un document HTML avec Beautiful Soup
- Objets Tag et NavigableString
- Aller plus loin avec le web scraping
- Pratique du web scraping
- Mini-projet Web Scraping avec BeautifulSoup
- TP
- Quiz
Section 4. Automatisation de l’accès aux données Web – Niveau intermédiaire
- Automatiser la navigation web
- Interaction du base du navigateur
- Gestion du glisser -déposer
- Fonction d’attente du selenium
- Fonction d’attente explicite de selenium
- Utiliser les fichiers d’exercice
- Comprendre le NLP
- Découvrir les domaines et les exemples d’application du NLP
- Installer Anaconda
- Aborder l’environnement Jupyter
- Comprendre le pipeline de modélisation NLP
- TP
- Quiz
Section 5. Automatisation de l’accès aux données Web – Niveau avancé
- Comprendre les requêtes API
- Créer des requêtes d’API
- Analyse via JSON
- Utilisation des clés API
- Lier les appels d’API
- Prochaines étapes
- Comprendre les requêtes API
- Créer des requêtes d’API
- Analyser le JSON
- Utiliser des clés d’API
- Lier les appels d’API
- Application – Mini-Projet
- TP
- Quiz
17- NLP – Natural Language Processing
Voir le programme
Section 1. Découvrir le NLP
1. Traitement du langage naturel avec Python
2. Connaître les prérequis théoriques et techniques
3. Utiliser les fichiers d’exercice
4. Comprendre le NLP
5. Découvrir les domaines et les exemples d’application du NLP
6. Installer Anaconda
7. Aborder l’environnement Jupyter
8. Comprendre le pipeline de modélisation NLP
9. Support pdf
– Utiliser les fichiers d’exercice
– Comprendre le NLP
– Découvrir les domaines et les exemples d’application du NLP
– Installer Anaconda
– Aborder l’environnement Jupyter
– Comprendre le pipeline de modélisation NLP
10. TP
11. Quiz
Section 2. Traiter un texte avec Python
1. Stocker un texte brut dans une structure de données Python
2. Utiliser Pandas pour lire les données
3. Comprendre les expressions régulières
4. Utiliser les expressions régulières avec le module Re de Python
5. Étudier les fonctions les plus populaires du module Re
6. Support pdf
– Stocker un texte brut dans une structure de données Python
– Utiliser Pandas pour lire les données
– Comprendre les expressions régulières
– Utiliser les expressions régulières avec le module Re de Python
– Étudier les fonctions les plus populaires du module Re
7. TP
8. Quiz
Section 3. Préparer les données
1. Aborder les étapes de préparation des données
2. Réaliser un exemple de nettoyage de données
3. Supprimer les stopwords
4. Réaliser le stemming avec NLTK
5. Pratiquer la lemmatization avec NLTK
6. Comparer le stemming et la lemmatization
7. Support pdf
– Aborder les étapes de préparation des données
– Supprimer les caractères de ponctuation
– Supprimer les stopwords
– Réaliser le stemming avec NLTK
– Réaliser la lemmatization avec NLTK
– Comparer le stemming et la lemmatization
9. TP
10. Quiz
Section 4. Transformer un texte en chiffres
1. Comprendre la vectorisation avec CountVectorizer
2. Utiliser CountVectorizer
3. Effectuer une vectorisation contextuelle avec N-Grams
4. Étudier TF-IDF
5. Utiliser TF-IDF
6. Appréhender le feature engineering
7. Ajouter des features aux données
8. Analyser les features
9. Support pdf
– Comprendre la vectorisation
– Comprendre la vectorisation avec CountVectorizer
– Utiliser CountVectorizer
– Effectuer une vectorisation contextuelle avec N-Grams
– Étudier TF-IDF
– Utiliser TF-IDF
– Appréhender le feature engineering
10. TP
11. Quiz
Section 5. Comprendre l’expérience machine learning – NLP
1. Apprendre la méthode K-fold
2. Comprendre la matrice de confusion d’un modèle de classification
3. Comprendre les mesures de performance d’un modèle NLP
4. Aborder l’overfitting (le surapprentissage)
6. Support pdf
– Apprendre la méthode K-fold
– La validation croisée avec Scikit-learn
– Matrice de Confusion d’un modèle de classification
– Les mesures de performance d’un modèle NLP
7. Quiz
Section 6. Réaliser un modèle de classification avec SVM
1. Modéliser en machine learning
2. Aborder l’algorithme Support Vector Machine
3. Utiliser le SVM avec scikit-learn et CountVectorizer
4. Tester le modèle de classification SVM
5. Mesurer les performances du modèle de classification SVM
6. Utiliser le SVM avec la cross-validation
7. Utiliser le SVM avec TF-IDF
7. Support pdf
– Machine Learning
– Aborder l’algorithme Support Vector Machine
– Utiliser le SVM avec scikit-learn
– Tester le modèle de classification
– Utiliser le SVM avec la cross-validation
8. TP
9. Quiz
Section 7. Réaliser un modèle de classification avec le Random forest
1. Aborder l’algorithme Random forest
2. Utiliser Random forest pour construire un modèle de classification
3. Mesurer les performances d’un modèle de classification Random forest
4. Utiliser Random forest avec K-fold
5. Support pdf
– Aborder l’algorithme Random forest
– Utiliser Random forest pour construire un modèle de classification
– Mesurer les performances d’un modèle de classification Random forest
– Utiliser Random forest avec K-fold
6. TP
7. Quiz
Section 8. Perfectionner un modèle avec l’hyperparamètre
1. Programmer un hyperparamètre avec le modèle SVM
2. Programmer un hyperparamètre avec Random forest
3. Évaluer les résultats d’un hyperparamètre
4. Tester GridSearchCV avec un SVM
5. Tester GridSearchCV avec Random forest
6. Détecter les features les plus importantes avec le Random forest
7. Homogénéiser les données avec TF-IDF
8. Tester Random forest sur des données homogènes
9. Sélectionner un modèle
10. Conclure sur le traitement du NLP avec Python
15. Support pdf
₋ Programmer un hyperparamètre avec le modèle SVM
₋ Programmer un hyperparamètre avec Random forest
₋ Évaluer les résultats d’un hyperparamètre
₋ Tester GridSearchCV avec un SVM
₋ Tester GridSearchCV avec Random forest
16. TP
17. Quiz
Section 9. Examen final
1. Synthèse du cours
2. TP Général
3. Examen final
18- Visualisation de données avec Excel / Power BI / Tableau
Voir le programme
EXCEL :
Section 1: Importation et exportation de données (partie 1)
1. Importer dans Excel à partir d’un fichier
- Importer des données à partir d’un classeur Excel
- Obtenir des données à partir d’un fichier texte ou CSV
- Importer des données depuis un fichier XML
- Importer des données depuis un fichier JSON
- Importer les données d’un dossier
- Récupérer les données d’une bibliothèque SharePoint
2. Importer dans Excel à partir d’une base de données
- Importer depuis une base de données SQL Server
- Importer depuis une base de données Microsoft Access
- Obtenir des données Analysis Services
- Importer des données SQL Server Analysis Services
- Importer des données depuis MySQL Server
3. Importer dans Excel à partir de Microsoft Azure
- Importer des données depuis une base de données SQL Server
- Importer des données depuis Azure SQL Data Warehouse et Azure
- HDInsight
- Importer des données depuis un stockage Blob Azure
- Importer des données depuis un stockage Table Azure
- Importer des données depuis Azure Data Lake Storage
4. Importer dans Excel à partir de services en ligne
- Importer des données depuis une liste SharePoint Online
- Importer des données depuis Microsoft Exchange Online
- Importer des données depuis Dynamics 365
- Importer des données depuis Facebook
5. Pdf
- Découvrir Power Query
- Importer dans Excel à partir d’un fichier
- Importer dans Excel à partir d’une base de données
- Importer dans Excel à partir de Microsoft Azure
- Importer dans Excel à partir de service en ligne
Section 2: Importation et exportation de données (partie 2)
1. Importer dans Excel à partir d’autres sources
- Importer des données depuis un tableau ou une plage
- Importer des données à partir d’un site web
- Importer des données depuis Microsoft Query
- Importer des données depuis SharePoint Server
- Importer des données à partir d’un flux OData
- Importer des données à partir d’Active Directory
- Importer des données à partir d’une requête vide
2. Aborder les fonctionnalités complémentaires
- Fusionner des sources multiples
- Ajouter des sources multiples
- Gérer les paramètres des sources de données
- Utiliser les options des requêtes
- Actualiser les données importées
3. Exporter dans d’autres formats
- Exporter un fichier au format texte
- Exporter un fichier au format CSV
- Exporter un fichier au format XML
- Exporter un fichier vers une page web
- Exporter un fichier comme classeur Excel
- Exporter un fichier en tant que modèle Excel
- Exporter un fichier aux formats SYLK et DIF
- Exporter un fichier au format PDF
- Exporter un tableau dans une liste SharePoint
- Exporter un tableau comme diagramme croisé dynamique
- Visio
- Découvrir les fonctions Exporter et Publier de Microsoft Excel
4. Pdf
- Importer dans Excel à partir d’autres sources
- Aborder les fonctionnalité complémentaires
- Exporter dans d’autres formats
Section 3: Analyse de données avec Power Pivot (partie 1)
1. Power Pivot
- Activer Power Pivot
- Comprendre l’intérêt du data storytelling
- Connaître les avantages et les inconvénients de Power Pivot
- Aborder les différences entre Power Pivot et Power BI
2. Exploiter les sources de données
- Découvrir l’interface de Power Pivot
- Importer des données depuis un fichier Excel
- Copier-coller les données
- Récupérer des données externes
- Importer les données d’un autre fichier Excel
- Transférer les données d’un fichier CSV
- Collecter les données d’un flux OData
- Importer des données avec Power Query
3. Manipuler Power Pivot
- Aborder les feuilles de données
- Utiliser les options de colonnes de données
- Mettre en forme et filtrer des données
- Trouver et modifier les métadonnées
- Créer et manipuler les perspectives
- Tirer parti des colonnes calculées
- Exploiter les mesures
- Connaître les propriétés de la création de rapports
- Employer les synonymes
4. Lecture Pdf
- Découvrir Power Pivot
- Exploiter les sources de données
- Manipuler Power Pivot
Section 4: Analyse de données avec Power Pivot (partie 2)
1. Mettre en place les relations
- Découvrir la vue diagramme et les relations entre tables
- Comprendre la cardinalité de la relation
- Assimiler le sens de filtrage de la relation
- Utiliser une table de date
2. Exploiter les indicateurs clés de performance (KPI)
- Mettre en place un KPI
- Créer un indicateur sur une mesure
3. Établir des hiérarchies
- Découvrir la hiérarchie
- Modifier les hiérarchies automatiques
- Créer une hiérarchie
4. Aborder les tableaux croisés dynamiques
- Générer un tableau croisé dynamique
- Manipuler les jeux de lignes ou de colonnes
- Convertir un tableau croisé dynamique en formules
- Partager un tableau croisé dynamique
5. Lecture Pdf
- Mettre en place les relations
- Exploiter les indicateurs clés de performance (KPI)
- Établir des hiérarchies
- Aborder les tableaux croisés dynamiques
- Section 5: Analyse de données avec Power Query
1. Découvrir Power Query
- Définir les objectifs de la formation
- Comprendre le complément Power Query pour Excel
- Comprendre les ETL et leur utilité
- Évaluer les avantages et les limites de l’éditeur de requête
- Comparer avec Power BI pour Desktop
2. Transformer ses données
- Gérer les erreurs de données
- Renommer les colonnes
- Définir les types de données
- Filtrer les données
- Traiter les doublons et les valeurs NULL
- Fractionner ou assembler des colonnes
- Formater les contenus des colonnes
- Transposer une table de données
- Chercher et remplacer des valeurs dans une colonne
- Regrouper les données
- Ajouter des colonnes personnalisées
3. Aller plus loin avec les transformations de données
- Combiner des requêtes
- Lier les tables et les requêtes
4. Pdf
- Mettre en place les relations
- Exploiter les indicateurs clés de performance (KPI)
- Établir des hiérarchies
- Aborder les tableaux croisés dynamiques
TABLEAU :
Introduction à la visualisation avec Tableau
- Comprendre les besoins auxquels répond Tableau
- Comprendre l’architecture générale
- Aborder les prérequis
- Découvrir le cycle de travail
- Installation de tableau
- Parcourir les fichiers source
Connexion à une source et importation des données
- Ouvrir Tableau
- Se connecter à un fichier Excel
- Vérifier les données
- Filtrer les chaînes de caractères
- Filtrer les données numériques
- Filtrer les données de type date
- Comprendre la notion de jointure
- Ajouter une deuxième feuille de calcul
- Ajouter un autre fichier
- Exécuter la requête
Création d’un visuel et préparation des données
- Explorer la structure d’ensemble d’un fichier Tableau
- Prendre en main l’interface de création des visualisations
- Créer un histogramme
- Utiliser l’étagère Repère pour améliorer le graphique
- Utiliser l’étagère Repère pour améliorer l’infobulle
- Définir le format d’affichage par défaut pour les mesures
- Créer une hiérarchie pour explorer les données
- Regrouper les valeurs d’une dimension
- Comprendre l’agrégation des mesures
- Actualiser les données de l’extrait
Aller plus loin avec les graphiques
- Travailler avec les dates
- Découvrir la variété des graphiques
- Filtrer un graphique
- Créer une matrice de graphiques
- Créer un graphique en miroir
- Créer un graphique à deux axes
- Ajouter une ligne de référence
- Créer un graphique en secteur
Travailler avec les tableaux
- Créer un tableau simple
- Créer un tableau simple multidimensionnel
- Ajouter une mise en forme conditionnelle
- Créer un tableau croisé
- Créer un tableau multimesure
Création des formules simples
- S’initier aux formules dans Tableau
- Créer un champ calculé simple
- Créer un champ calculé conditionnel
- Créer une mesure discrète
- Créer et afficher un paramètre
- Utiliser un paramètre dans une formule
Création d’un tableau de bord
- Découvrir l’interface d’assemblage d’un tableau de bord
- Démarrer et assembler un tableau de bord
- Assembler un tableau de bord à l’aide de différents éléments
- Paramétrer les interactivités du tableau de bord
Atelier pratique
POWER BI :
Introduction à Power Bi
- Présentation De Power BI
- Caractéristiques de Power Bi
- Composants de Power BI
- Cycle de travail dans Power BI Desktop
- Configuration des options de Power BI
Création de requêtes basées sur Excel
- Importer un fichier Excel composé d’une feuille
- Importer un fichier Excel composé de plusieurs feuilles
- Importer un TCD Excel
- Atelier pratique : Création de requêtes basées sur Excel
Préparation des données
- Choix des colonnes
- Nettoyage des données
- Conversion des données
- Transformation des données
- Ajout des colonnes selon 2 méthodes
- Fusion des requêtes
- Combinaison des requêtes
- Atelier pratique : Préparation des données
Création de requêtes sur une base de données
- Appréhender l’import et la requête directe
- Importer les tables
- Atelier pratique : Création de requêtes sur une base de données
Création de requêtes sur d’autres sources
- Importer plusieurs fichiers Excel
- Créer une requête sur un fichier TXT ou CSV
- Effectuer une requête à partir du web
- Requêter à partir d’un fichier PDF
- Atelier pratique : Création de requêtes sur d’autres sources
Organisation des tables et des relations
- Utiliser la vue Modèle
- Mettre en place les relations
- Connaître les bonnes pratiques d’organisation des tables
- Formater et organiser les données
- Créer une mesure
- Atelier pratique : Organisation des tables et des relations
Création de la table de temps
- Nécessité d’une table de temps
- Créer la table à l’aide d’un script DAX
- Associer la table au modèle et ajuster les champs
- Déterminer le nombre de tables du temps
- Atelier pratique : Création de la table de temps
Mise en place des principaux graphiques et tableaux
- Aborder les règles d’ergonomie et de composition d’un rapport
- Découvrir l’interface de Power BI
- Choisir judicieusement les couleurs
- Créer et configurer un histogramme
- Créer et configurer un graphique en courbe
- Créer un graphique en secteur
- Créer une carte
- Créer une carte à plusieurs lignes
- Ajouter une zone de texte et une image pour le titre
- Créer une carte géographique
- Atelier pratique : Mise en place des principaux graphiques et les tableaux
Filtrage des données
- Créer un segment
- Synchroniser les segments entre plusieurs pages
- Utiliser le volet Filtre
- Atelier pratique : Filtrage des données
Utilisation des tableaux
- Créer un tableau simple
- Créer un tableau croisé
- Dupliquer la mise en forme
- Atelier pratique : Utilisation des tableaux
Exportation des données
- Récupérer les données au format Excel/CSV et exporter au format PDF
- Introduction à Power BI Service
- Atelier pratique : Exportation des données
Informations pratiques
Suivant le baromètre Besoin en Main d’Œuvre 2019 (BMO 2019) et la DARES, le nombre de postes à créer pour le consultant Big Data ainsi que les difficultés de recrutement en 2019 sont comme suit
Nombre de postes à pourvoir
National
Île-de-France
Auvergne-Rhône-Alpes
Occitanie
Quels sont les chiffres associés aux postes et à la formation ?
Salaire pour un junior en moyenne
Salaire pour un senior en moyenne
Recrutements jugés difficiles
%
National
%
Île-de-France
%
Auvergne-Rhône-Alpes
%
Occitanie
La formation « Big Data enginnering et Data scientist » va vous ouvrir un large panel de possibilités et vous permettre d’exercer les métiers suivants :
✔ Consultant Big Data
✔ Data Architect
✔ Data engineering
✔ Data Analyst
✔ Data Scientist avec Python
✔ Data Scientist avec R
✔ Data Scientist et Intelligence artificielle
✔ Architect cloud AWS, Azure ou GCP pour Big Data
✔ Développeur Full Stack Big Data

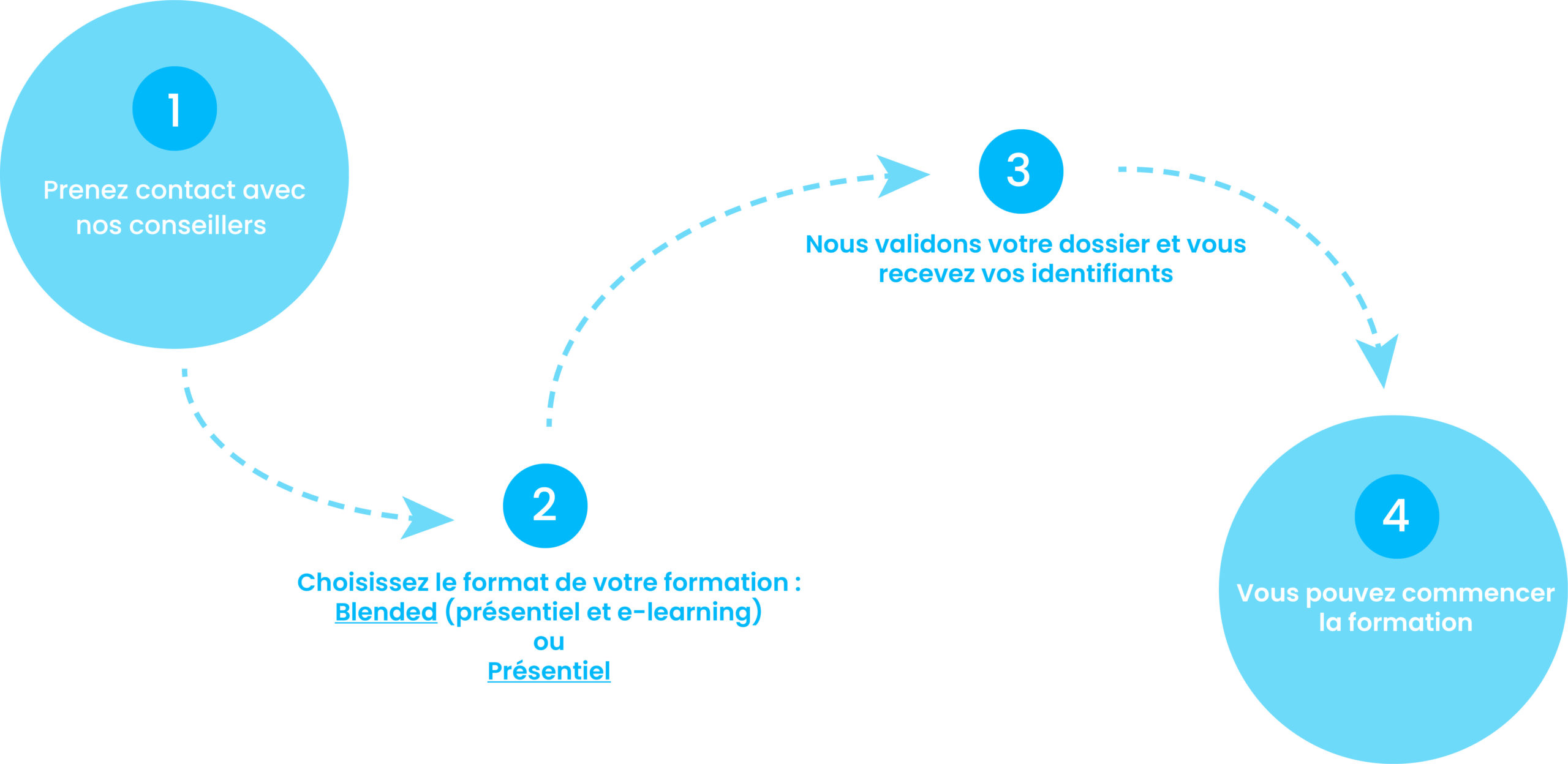
Comment suivre une formation chez nous ?
2. Choisissez le format de votre formation : Blended (présentiel et e-learning) ou présentiel
3. Nous validons votre dossier et vous recevez vos identifiants.
4. Vous pouvez commencer la formation.
Financez votre formation !
Financement CPF
CPF de transition
PDC
VAE
Contrat PRO
AFPR
AIF
POEc
POEi
Découvrez nos solutions
CPF de transition – CPF de transition pour une Reconversion Professionnelle
PDC- Plan de Développement de Compétences de l’entreprise.
VAE – Validation des Acquis de l’Expérience
Contrat PRO – Contrat d’alternance ou de Professionnalisation
AFPR – Action de Formation Préalable à l’Embauche
AIF – Aide Individuelle à la Formation par Pôle Emploi
POEc – Préparation Opérationnelle Emploi Collective
POEi – Préparation Opérationnelle Emploi Individuelle