Formation Administration de Base de Données SQL Serveur
Devenez Administrateur SQL Server
38 jours
100% finançable
Formation RNCP
Jours de formation
Solutions de financement
Une formation pour qui ?
- Le parcours certifiant Administration Base de Données SQL Server s’adresse aux :
Salarié d’entreprise, demandeur d’emploi et toute personne en reconversion. - Toute personne souhaitant évoluer vers l’administration de bases de données et les technologies SQL Server.
- Développeur informatique JAVA, .NET, PHP ou Mobile.
- Ingénieur d’étude ou Architecte système et logiciel ou Consultant Business Intelligence
L’Administrateur de Base de Données SQL Server a pour principale fonction d’organiser et de gérer en toute fiabilité les systèmes de Gestion des données de l’entreprise. Il doit en assurer la cohérence, la qualité et la sécurité.
Il doit être en mesure d’Installer, de configurer et d’administrer les bases de données. Gérer l’espace de stockage physique et logique des bases et veiller à l’intégrité des données stockées.
L’Administrateur/Développeur Base de Données SQL Server maîtrise l’aspect technique et fonctionnel pour la mise
en place d’une solution BI « Business Intelligence », à savoir : SSIS pour l’intégration de données, SSAS pour l’analyse de données et SSRS pour le reporting.
Pré-requis
Pas de prérequis nécessaire pour cette formation. Toutefois, avoir des connaissances en base de données relationnelles et en UML est un plus.
A l’issue du cursus certifiant « Administration Base de Données SQL Server », les certifiés seront en mesure de :
- Définir et analyser les besoins des utilisateurs, rédiger un cahier des charges technique et fonctionnel.
- Modéliser les données et établir le schéma physique.
- Créer la Base de Données.
- Effectuer des tests sur des données exemples.
- Développer des composants sous forme de procédures stockées afin d’implémenter le traitement dans la Base de Données.
- Garantir la disponibilité et l’accessibilité des informations.
- Construire des algorithmes pour le traitement de données
- Mettre en place des solutions BI « BusinessIntelligence »
- Maîtriser les services SQL Server pour l’intégration, l’analyse et le reporting : SSIS, SSAS, SSRS Sécuriser une Base de Données SQL Server.
- Définir les droits d’accès pour sécuriser l’information
- Mettre en place des procédures de sauvegarde et de restauration
Programme détaillé
Introduction BDD SQL
Voir le programme
Introduction aux bases de données
- Introduction aux bases de données relationnelles
- Autres types de base de données
- L’analyse des données
- Langues de la base de données.
Modélisation de données
- Modélisation des données
- Modèle de base de données ANSI / SPARC
- Modélisation de la relation d’entité.
Normalisation
- Pourquoi normaliser les données?
- Niveaux de normalisation
- Denormalisation.
Des Relations
- Cartographie de schéma
- Intégrité référentielle.
Performance
- Indexage
- Performance de la requête
- Concurrence.
Vues
- Procédures stockées
- Autres objets de base de données.
Atelier et cas pratique
Transact SQL pour SQL Server
Voir le programme
Introduction à Microsoft SQL Server
- L’architecture de base de SQL Server
- Éditions et versions SQL Server
- Mise en route de SQL Server Management Studio.
Introduction à la requête T-SQL
- Présentation de T-SQL
- Ensembles compréhensifs
- Comprendre la logique des prédictions
- Comprendre l’ordre logique des opérations dans les instructions SELECT.
Ecriture des requêtes SELECT
- Rédaction d’instructions SELECT simples
- Élimination des doublons avec DISTINCT
- Utilisation de colonnes et d’alias de table
- Rédaction d’expressions simples CASE.
Atelier et Cas pratique
Tri et filtrage des données
- Tri des données
- Filtrage des données avec les prédicats
- Filtrage des données avec TOP et OFFSET-FETCH
- Travailler avec des valeurs inconnues.
Utilisation des types de données SQL Server 2016
- Présentation des types de données SQL Server 2016
- Utilisation des données personnelles
- Travailler avec les données de date et d’heure.
Utilisation de DML pour modifier les données
- Insertion de données
- Modification et suppression de données.
Atelier et cas pratiques
Utilisation des fonctions intégrées
- Ecriture de requêtes avec fonctions intégrées
- Utilisation des fonctions de conversion
- Utilisation des fonctions logiques
- Utiliser des fonctions pour travailler avec NULL.
Groupement et agrégation de données
- Utilisation des fonctions agrégées
- Utilisation de la clause GROUP BY
- Filtrage des groupes avec HAVING.
Utilisation de sous-requêtes
- Écriture de sous-requêtes auto-contenues
- Composer des sous-requêtes corrélées
- Utilisation du prédicat EXISTS avec sous-requêtes.
Atelier et cas pratique
Utilisation des expressions de table
- Utilisation des vues
- Utilisation de fonctions de table intégrées
- À l’aide de tables dérivées
- Utilisation des expressions de table commune.
Utilisation des opérateurs Set
- Ecriture de requêtes auprès de l’opérateur UNION
- Utilisation EXCEPT et INTERSECT
- Utilisation de l’APPLICATION.
Atelier et cas pratique
Administration BDD SQL
Voir le programme
Introduction
- Sécurité du serveur SQL
- Authentification des connexions à SQL Server
- Autoriser les connexions à se connecter à des bases de données
- Autorisation dans les serveurs
- Bases de données partiellement contenues.
Histoire de SQL Server
Evolution des fonctionnalités de SQL Server
Attribution de serveurs et de fonctions de base de données
- Travailler avec les rôles du serveur
- Travailler avec des rôles de base de données fixes
- Attribution de rôles de base de données définis par l’utilisateur.
Dessins de table avancés
- Partitionnement des données
- Compressing Data
- Tables temporelles.
Autoriser les utilisateurs à accéder aux ressources
- Autoriser l’accès des utilisateurs aux objets
- Autoriser les utilisateurs à exécuter le code
- Configuration des autorisations au niveau du schéma.
Atelier et cas pratique
Protection des données avec cryptage et audit
- Options pour auditer l’accès aux données dans SQL Server
- Mise en œuvre de l’audit SQL Server
- Gestion de l’audit SQL Server
- Protection des données avec cryptage.
Modèles de récupération et stratégies de sauvegarde
- Comprendre les stratégies de sauvegarde
- Journal des transactions SQL Server
- Stratégies de sauvegarde de planification.
Sauvegarde des bases de données SQL Server
- Sauvegarde des bases de données et des journaux de transactions
- Gestion des sauvegardes de base de données
- Options de base de données avancées.
Restauration des bases de données SQL Server
- Comprendre le processus de restauration
- Restauration de bases de données
- Scénarios de restauration avancée
- Récupération ponctuelle.
Automatisation de la gestion SQL Server
- Automatisation de la gestion SQL Server
- Utilisation d’un agent SQL Server
- Gestion des tâches de l’agent SQL Server
- Gestion multi-serveurs.
Atelier et cas pratiques
Configuration de l’agent Security pour SQL Server
- Comprendre la sécurité de l’agent SQL Server
- Configuration des informations d’identification
- Configuration des comptes proxy.
Surveillance de SQL Server avec des alertes et des notifications
- Configuration du courrier de la base de données
- Surveillance des erreurs SQL Server
- Configuration des opérateurs, alertes et notifications
- Alertes dans la base de données Azure SQL.
-
Introduction à la gestion de SQL Server en utilisant PowerShell
- Configurer SQL Server à l’aide de PowerShell
- Administrer SQL Server à l’aide de PowerShell
- Maintenir l’environnement SQL Server à l’aide de PowerShell
- Gestion des bases de données Azure SQL Server via PowerShell.
Tracer l’accès à SQL Server avec des événements étendus
- Concepts fondamentaux des événements étendus
- Travailler avec des événements étendus.
Atelier et Cas pratique
Surveillance de SQL Server
- Activité de surveillance
- Capture et gestion des données de performance
- Analyse des données de performance collectées
- Utilitaire SQL Server.
Dépannage de SQL Server
- Méthode de dépannage SQL Server
- Résolution des problèmes liés au service
- Résolution des problèmes de connexion et de connectivité
- Dépannage des problèmes communs.
Importation et exportation de données
- Transfert de données vers / depuis SQL Server
- Importation et exportation de données de table
- Utilisation de BCP et BULK INSERT pour importer des données
- Déploiement et mise à niveau des applications de niveau de données.
Atelier et Cas pratique
Développement BDD SQL Server
Voir le programme
Introduction au développement de bases de données
- Introduction à la plate-forme SQL Server
- Tâches de développement de base de données SQL Server.
Conception et mise en œuvre de tableaux
- Tableaux de conception
- Types de données
- Travailler avec des schémas
- Création et modification de tableaux.
Dessins de table avancés
- Partitionnement des données
- Compressing Data
- Tables temporelles.
Assurer l’intégrité des données grâce à des contraintes
- Application de l’intégrité des données
- Implémentation de l’intégrité du domaine
- Entité de mise en œuvre et intégrité référentielle.
Atelier et cas pratique
Gérer les index
- Plans d’exécution
- Utilisation de l’ETTD.
Indexation Columnstore
- Introduction aux index Columnstore
- Création d’index de classe Columnstore
- Les index de colonnes de travail.
Conception et réalisation de vues
- Introduction aux vues
- Création et gestion de vues
- Considérations relatives à la performance pour les vues.
Conception et mise en œuvre de procédures stockées
- Introduction aux procédures stockées
- Travailler avec des procédures stockées
- Mise en œuvre des procédures stockées paramétrées
- Contrôle du contexte d’exécution.
Atelier et cas pratiques
Tuning et Optimisation SQL Server
Voir le programme
Architecture SQL Server, planification et attente
- Composants du serveur SQL et système d’exploitation SQL
- Windows Scheduling vs SQL Scheduling
- Attentes et files d’attente.
E/S SQL Server
- Concepts de base
- Solutions de stockage
- Configuration et test d’E / S.
Structures de base de données
- Structure interne de la base de données
- Fichier de données internes
- TempDB Internals.
Atelier et cas pratique
Mémoire serveur SQL
- Mémoire Windows
- Mémoire serveur SQL
- OLTP en mémoire.
Concurrence et transactions
- Concurrence et transactions
- Verrouillage interne.
Statistiques et index internes
- Statistiques internes et estimation de cardinalité
- Index interne
- Indices des magasins de colonnes.
Atelier et cas pratique
Analyse des requêtes et de la planification des requêtes
- Exécution de la requête et optimisation interne
- Analyser les plans de requêtes.
Mise en cache et recompilation des plans
- Plan du cache interne
- Dépannage des problèmes de cache de plan
- Query Store.
Evénements prolongés
- Concepts fondamentaux des événements étendus
- Mise en œuvre d’événements étendus.
Atelier et cas pratique
Surveillance, suivi et regroupement
- Surveillance et suivi
- Bâle et benchmarking.
Dépannage des problèmes de performance courants
- Résoudre les performances du processeur
- Dépannage des performances de la mémoire
- Dépanner les performances d’E / S
- Dépannage des performances simultanées
- Dépannage des performances TempDB.
Atelier et Cas pratique
Introduction à l’Intégration Services (SSIS)
Voir le programme
Une visite guidée des services d’intégration
- Comprendre les services d’intégration
- Explorer et exécuter un paquet de services d’intégration dans BIDS
- Explorer et exécuter un forfait en dehors de BIDS.
Flux de contrôle
- Vue d’ensemble de Control Flow dans Integration Services
- Travailler avec les tâches Workflow
- Contraintes de priorité.
Flux de données
- La tâche de flux de données
- Visualiseurs de données
- Transformations de flux de données.
Variables et configurations
- Comprendre les variables
- Utilisation de variables dans le flux de contrôle
- Utilisation de variables dans le flux de données
- Configurations
- Utilisation de variables et de configurations entre les packages.
Flux de contrôle avancé
- Vue d’ensemble du flux de contrôle avancé
- Utilisation des conteneurs
- Support aux transactions dans les services d’intégration.
Gestion des erreurs et enregistrement
- Quand les choses vont mal
- Points de contrôle
- Manipulation des erreurs et débogage
- Enregistrement des emballages
- Gestion des événements.
Flux de données avancé
- Transformations synchrones et asynchrones
- Utilisation des transformations avancées
- Manipulation lente des dimensions changeantes.
Déploiement du package
- Déploiement de packages
- Créer un utilitaire de déploiement de package
- Installation d’un paquet
- Redéploiement des packages mis à jour.
Gestion des paquets
- Aperçu de la gestion des paquets
- Gestion des packages Integration Services
- Exécution des paquets
- Sécurité des services d’intégration.
Scripts et composants personnalisés
- Extension des fonctionnalités des services d’intégration par code
- Les scripts dans les flux de contrôle avec la tâche de script
- Scripting dans les flux de données avec le composant Script
- Composants des services personnalisés d’intégration.
Les meilleures pratiques
- Meilleures pratiques pour l’utilisation des services d’intégration
- Meilleures pratiques pour le développement et le développement de paquets
- Meilleures pratiques de flux de données
- Meilleures pratiques de déploiement et de gestion.
Aller au-delà de l’ETL
- Utilisation des services d’intégration au-delà de l’ETL
- Migration et maintenance de serveurs SQL avec services d’intégration
- Travailler avec Analysis Services
- Utilisation de Windows Management Instrumentation.
Atelier et Cas pratique
Introduction à SQL Server Analysis Services (SSAS)
Voir le programme
Qu’est-ce que Microsoft Business Intelligence?
- Définir le Business Intelligence
- Comprendre la structure du cube
- Déployer et afficher un cube d’échantillons
- Afficher un cube en utilisant Excel
- Afficher un cube en utilisant SQL Reporting Services.
Modélisation OLAP
- Comprendre la modélisation OLAP de base (schéma en étoile)
- Comprendre la modélisation dimensionnelle (étoiles et flocons de neige)
- Comprendre la mesure (fait) et la modélisation de cube
- Modèle avec SQL Server Business Intelligence Development Studio (BIDS).
Utilisation de SSAS dans BIDS
- Comprendre l’environnement de développement
- Créer des sources de données
- Créer des vues de source de données
- Créer des cubes en utilisant l’Assistant Cube.
SSAS intermédiaire
- Découvrez comment créer des indicateurs clés de performance (KPI)
- Découvrez comment créer des perspectives
- Découvrez comment créer des traductions pour cubes et dimensions
- Examinez les trois types d’objets d’action SSAS: régulier, analyse et rapports.
SSAS avancé
- Travailler avec des tableaux de faits multiples et la sous-liste d’utilisation de la dimension dans BIDS
- Explorez les types de dimensions avancées
- Découvrez comment utiliser le Business Intelligence Wizard
- Comprendre l’écriture dans les dimensions
- Examiner les mesures semi-additifs dans les cubes OLAP.
Stockage et agrégation de cubes
- Afficher les dessins d’agrégations
- Personnaliser les conceptions d’agrégation
- Implémenter la mise en cache proactive
- Utiliser les divisions relationnelles et SSAS
- Personnaliser le traitement des cubes et des cotes.
Introduction aux requêtes MDX
- Comprendre la syntaxe MDX de base
- Utilisez l’éditeur de requête MDX dans SSMS
- Comprendre les fonctions et tâches MDX communes
- Revoir les fonctions de MDX nouvelles à SSAS 2008.
Expressions MDX
- Comprendre le sous-formulaire de calcul
- Découvrez comment ajouter des membres calculés
- Découvrez comment ajouter des commandes de script MDX
- Découvrez comment ajouter des assemblages .NET.
Introduction à l’exploration de données
- Comprendre les concepts d’exploration de données
- Examinez les Algorithmes auxquels SSAS comprend
- Envisager les clients d’exploration de données
- Comprendre le traitement de la structure minière.
Administration SSAS
- Mettre en œuvre SSAS Security
- Implémentez les scripts XMLA dans SSMS
- Déploiement et synchronisation des bases de données
- Comprendre la sauvegarde et la restauration de la base de données SSAS.
Administration et optimisation avancées
- Mettre en œuvre SSIS pour gérer les bases de données SSAS
- Explorez le regroupement
- Explorez les options de scalabilité
- Comprendre l’optimisation et la performance des performances.
Introduction aux clients SSAS
- Rapports de conception à l’aide de Reporting Services
- Concevoir des rapports à l’aide de Report Builder
- Implémenter les tableaux et graphiques pivotants Excel 2007
- Utilisez Excel 2007 comme client de l’exploration de données
- Examiner Microsoft Office SharePoint Server 2007.
Atelier et Cas pratique
Service de Rapport SQL Server (SSRS)
Voir le programme
Introduction
- SSRS Vue d’ensemble et outils
- Caractéristiques des services de rapports
- Outils disponibles avec SQL Server 2008 R2
- Documentation SQL Servers.
Travailler avec des solutions et des projets
- Utilisation des outils de données SQL Server
- Comprendre les solutions et les projets
- Utilisation de l’interface Visual Studio.
Création de rapports de base
- Qu’est-ce qu’une source de données?
- Qu’est-ce qu’un ensemble de données?
- Utilisation de l’Assistant Rapport
- Qu’est ce que Tablix?
- Création d’un rapport tabulaire
- Création d’un rapport de liste
- Qu’est-ce qu’une matrice?
- Déploiement d’un projet.
Atelier et cas pratique
Formatage des rapports
- Travailler avec des boîtes de texte
- Formatage de texte enrichi
- Gestion des boîtes de texte
- Dessiner des lignes et des boîtes
- Images
- En-têtes et pieds de page
- Ajout d’une carte de document
- Rapports de rendu.
Expressions personnalisées
- Comprendre les expressions
- Définition des expressions
- Travailler avec des variables de rapport
- Comprendre les fonctions Lookup, LookupSet et Multilookup
- Échantillons d’expression.
Résumer et trier
- Créer des groupes
- Parent / Enfant vs Groupements adjacents
- Ajout de totaux et d’agrégations
- Création d’agrégats d’agrégats.
Ajouter une souplesse avec les paramètres
- Ajouter des paramètres à un rapport
- Paramètres du rapport par rapport aux paramètres de requête
- Gérer les propriétés des paramètres du rapport
- Utiliser des paramètres avec des requêtes SQL et des procédures stockées
- Travailler avec des paramètres en cascade
- Trier en fonction d’un paramétrage
- Rapports filtrés.
Articles de rapport améliorés
- Graphiques
- Jauges
- Ajouter une carte à un rapport
- Barre de données, indicateurs et éléments du rapport Sparkline
- Regarder les régions de données
- Subreports et rapports de forage
- Travailler avec des rapports de forage.
Utilisation de Report Manager
- Déploiement
- Navigateur de gestionnaire de rapports
- Comprendre les autorisations
- Affichage des rapports
- Utilisation de sources de données partagées
- Gestion des rapports.
Atelier et Cas pratique
Business Intelligence
Voir le programme
Introduction à l’entreposage de données
- Vue d’ensemble de l’entreposage de données
- Planification d’une solution de BI
- Éléments d’une solution de BI
- Planification d’un projet de BI
- La plate-forme de BI Microsoft.
Planification de l’infrastructure de Business Intelligence SQL Server
- Considérations relatives à l’infrastructure de BI
- Matériel de stockage de données de planification
- Conception d’un entrepôt de données.
Présentation de la conception des entrepôts de données
- Conception de tables de dimensions
- Tables de conception FACT.
Atelier cas pratique
Conception d’une solution ETL
- Présentation de ETL (Extract, Transform, Load)
- Planification de l’extraction des données
- Planification des transformations de données
- Planification du chargement des données.
Conception de modèles de données analytiques
- Introduction aux modèles de données analytiques
- Conception de modèles de données analytiques.
Atelier cas pratique
Planification d’une solution de livraison de BI
- Considérations relatives à la livraison de BI
- Scénarios de rapports communs.
Choisir un outil de reporting
- Conception d’une solution Reporting Services
- Planification d’une solution de reporting
- Conception de rapports
- Consistance du rapport de planification
Atelier cas pratique
Conception d’une solution de reporting basée sur Excel
- Utilisation d’Excel pour le reporting et l’analyse des données
- PowerPivot en Excel
- Power View in Excel.
Planification d’une solution de SharePoint Server BI
- Introduction à SharePoint Server en tant que plateforme BI
- Planification de la sécurité pour une solution de SharePoint Server BI
- Configuration de Reporting Reporting Services
- Planification de la configuration PowerPivot
- Planification des services PerformancePoint.
Atelier cas pratique
Services de données de base
- Introduction aux services de données de base
- Surveillance et optimisation d’une solution de BI
- Aperçu du suivi de la BI
- surveillance et optimisation de l’entrepôt de données
- Surveillance et analyse des services d’analyse
- Surveillance et optimisation des services de reporting.
Utilisation d’une solution de BI
- Vue d’ensemble des opérations de BI
- Opérations ETL
- Opérations d’entrepôt de données
- Opérations des services d’analyse
- Opérations des services de rapports.
Atelier cas pratique
Data Warehouse
Voir le programme
Introduction à l’entreposage de données
- Vue d’ensemble de l’entreposage de données
- Considérations relatives à une solution de stockage de données.
Infrastructure de stockage de données de planification
- Considérations relatives à l’infrastructure du Data Warehouse
- Matériel de stockage de données de planification.
Conception et implémentation d’un entrepôt de données
- Présentation de la conception des entrepôts de données
- Conception de tables de dimensions
- Concevoir des tables de faits
- Conception physique pour un entrepôt de données.
Atelier cas pratique
Création d’une solution ETL avec SSIS
- Introduction à ETL avec SSIS
- Exploration des sources de données
- Mise en œuvre du flux de données
- Mise en œuvre du flux de contrôle dans un package SSIS
- Introduction au flux de contrôle
- Création de packages dynamiques
- Utilisation des conteneurs
- Gestion de la cohérence
- Débogage et dépannage des packages SSIS
- Débogage d’un package SSIS
- Enregistrement des événements du package SSIS
- Manipulation des erreurs dans un package SSIS.
Atelier cas pratique
Mise en œuvre d’une solution d’extraction de données
- Extraction de données de planification
- Extraction de données modifiées.
Chargement des données dans un entrepôt de données
- Planification des charges de données
- Utilisation de SSIS pour les charges incrémentales
- Utilisation des techniques de chargement Transact-SQL.
Application de la qualité des données
- Introduction à la qualité des données
- Utilisation des services de qualité des données pour nettoyer les données
- Utilisation des services de qualité des données pour nettoyer les données.
Atelier cas pratique
Services de données de base
- Introduction aux services de données de base
- Mise en œuvre d’un modèle de services de données de base
- Gestion des données de base
- Création d’un concentrateur de données maître.
Extension des services d’intégration SQL Server
- Utilisation de scripts dans SSIS
- Utilisation de composants personnalisés dans SSIS.
Atelier cas pratique
Déploiement et configuration des packages SSIS
- Vue d’ensemble du déploiement de SSIS Deployer des projets SSIS
- Planification de l’exécution du paquet SSIS.
Atelier cas pratique
Informations pratiques
Suivant le baromètre Besoin en Main d’Œuvre 2019 (BMO 2019) et la DARES, le nombre de postes à créer pour le consultant Big Data ainsi que les difficultés de recrutement en 2019 sont comme suit
Nombre de postes à pourvoir
National
Île-de-France
Auvergne-Rhône-Alpes
Occitanie
Quels sont les chiffres associés aux postes et à la formation ?
Salaire pour un junior en moyenne
Salaire pour un senior en moyenne
Recrutements jugés difficiles
%
National
%
Île-de-France
%
Auvergne-Rhône-Alpes
%
Occitanie
Le certificat « Administration Base de Données SQL » va vous ouvrir un large
panel de possibilités et vous permettre d’exercer les métiers suivants :
✔ Consultant BI
✔ Administrateur Base de Données SQL Server
✔ Développeur Base de Données SQL Server
✔ Data Architect après avoir suivi la formation Cegefos : Big Data Architect

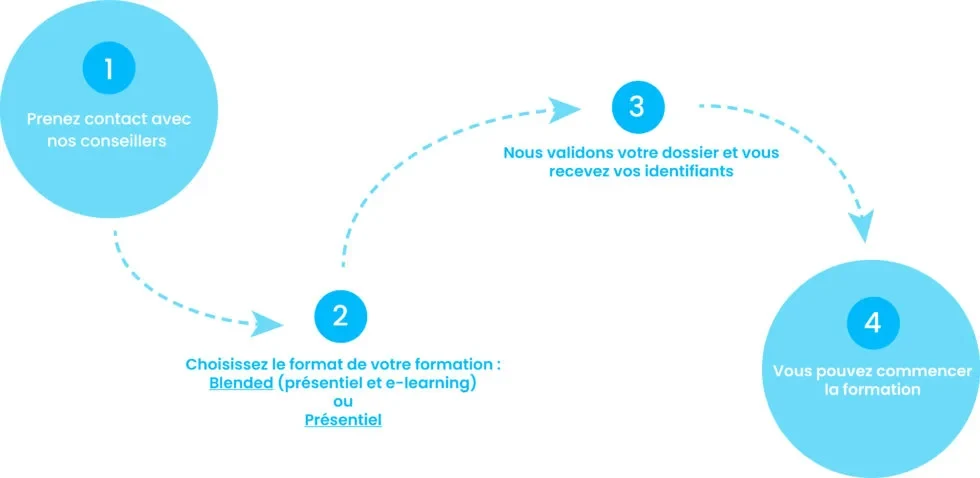
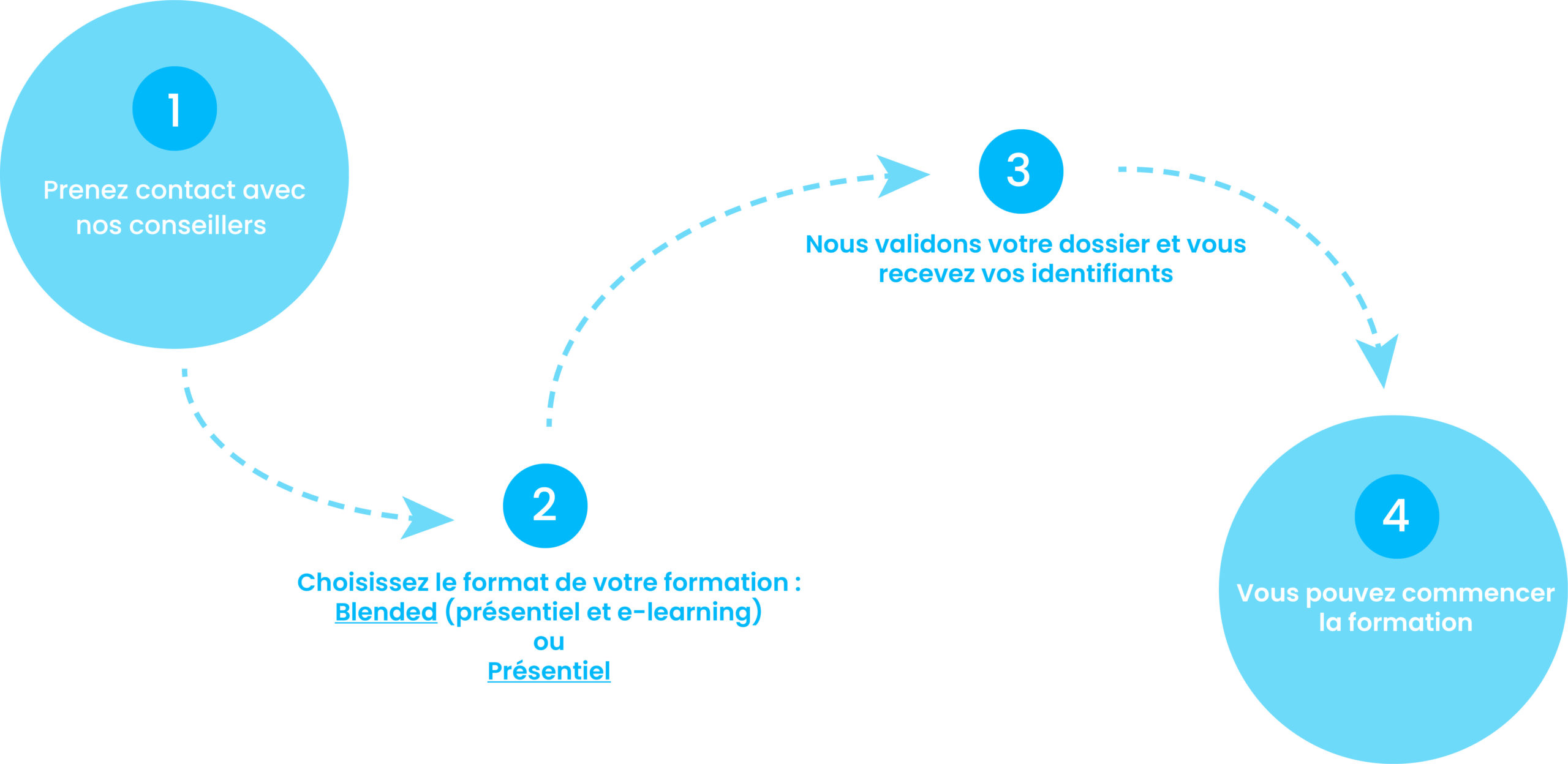
Comment suivre une formation chez nous ?
2. Choisissez le format de votre formation : Blended (présentiel et e-learning) ou présentiel
3. Nous validons votre dossier et vous recevez vos identifiants.
4. Vous pouvez commencer la formation.
Financez votre formation !
Financement CPF
CPF de transition
PDC
VAE
Contrat PRO
AFPR
AIF
POEc
POEi
Découvrez nos solutions
CPF de transition – CPF de transition pour une Reconversion Professionnelle
PDC- Plan de Développement de Compétences de l’entreprise.
VAE – Validation des Acquis de l’Expérience
Contrat PRO – Contrat d’alternance ou de Professionnalisation
AFPR – Action de Formation Préalable à l’Embauche
AIF – Aide Individuelle à la Formation par Pôle Emploi
POEc – Préparation Opérationnelle Emploi Collective
POEi – Préparation Opérationnelle Emploi Individuelle